관련 링크 : https://arxiv.org/abs/1911.04252
본 논문은 ImageNet 분류 성능을 향상시키는 Noisy Student 방법을 제시한다. 이는 기존 연구인 Self-Training(Knowledge Distillation), Semi-supervised learning과 관련성이 깊다. 따라서 먼저 이것들을 간략히 소개하고, Noisy Student Training을 소개하겠다.
Self-Training(Knowledge Distillation)
Self-training은 unlabeled 데이터셋을 이용해 모델의 성능을 향상시키는 방법이다. 먼저 labeled 데이터로 Teacher network를 학습시키고, 이를 이용해 unlabeled 데이터의 pseudo-label을 만든 후, 이들을 이용해 Student network를 학습시킨다.
Knowledge Distillation은 self-training과 방법은 동일하지만, 좋은 성능을 내는 기존 모델을 이용해 더 적은 파라미터를 가진 작은 모델을 얻는 방법으로, unlabeled 데이터를 사용하지 않고 student network가 teacher보다 작다는 차이가 있다. Knowledge Distillation의 과정은 다음 그림과 같이 간략히 표현할 수 있다.
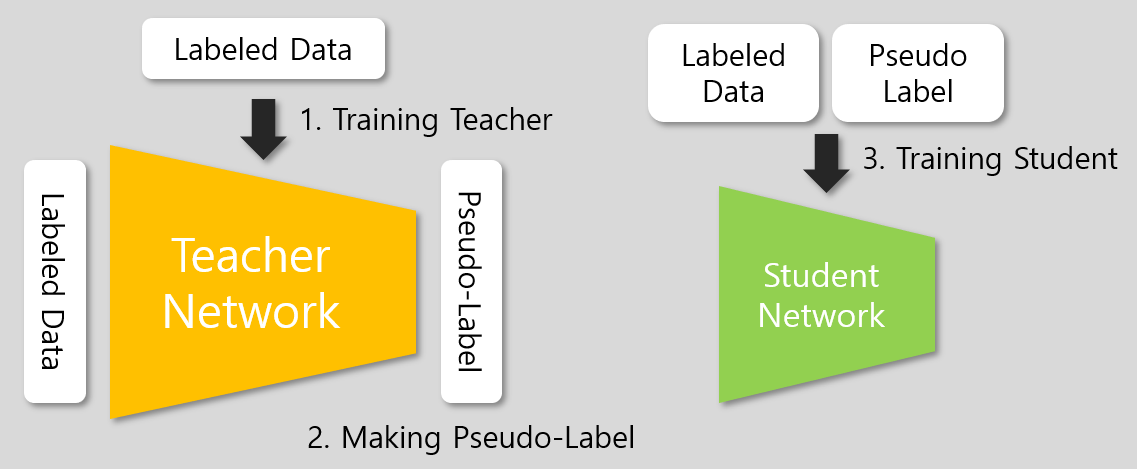
3단계에는 labeled 데이터와 pseudo-label이 할당된 labeled 데이터가 이용된다.
Semi-Supervised Learning
Semi-Supervised Learning은 소량의 labeled 데이터와 대량의 unlabeled 데이터가 있는 환경에서 네트워크의 성능을 향상시키기 위해 사용되는 방법이다. Self-training과 목적은 비슷하지만 약간의 차이가 있다.
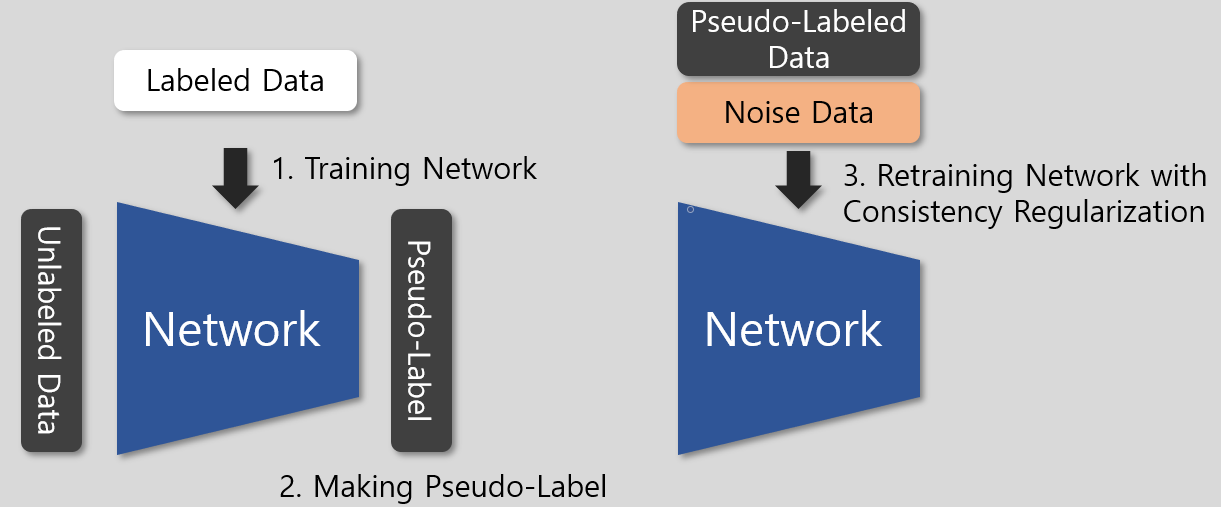
3단계에는 pseudo-label이 할당된 unlabeled 데이터와, 그 데이터에 noise를 추가한 데이터가 사용된다. Noise는 데이터에 적용되는 data augmentation, 모델에 적용되는 dropout, stochastic depth를 의미한다.
간단히 위 그림처럼 표현할 수 있는데, 그림에서도 나타나듯 self-training과 달리 psuedo-label을 만드는 네트워크와 학습시키는 네트워크가 동일하다. 또 Noise라는 부분이 생겼는데, 이는 teacher와 student가 동일한 네트워크라 teacher에서 만드는 pseudo-label의 신뢰성을 보장할 수 없기 때문에 추가되었다.
좀 더 명확한 이해를 위해 3단계를 구체적으로 표현하면 다음과 같다.
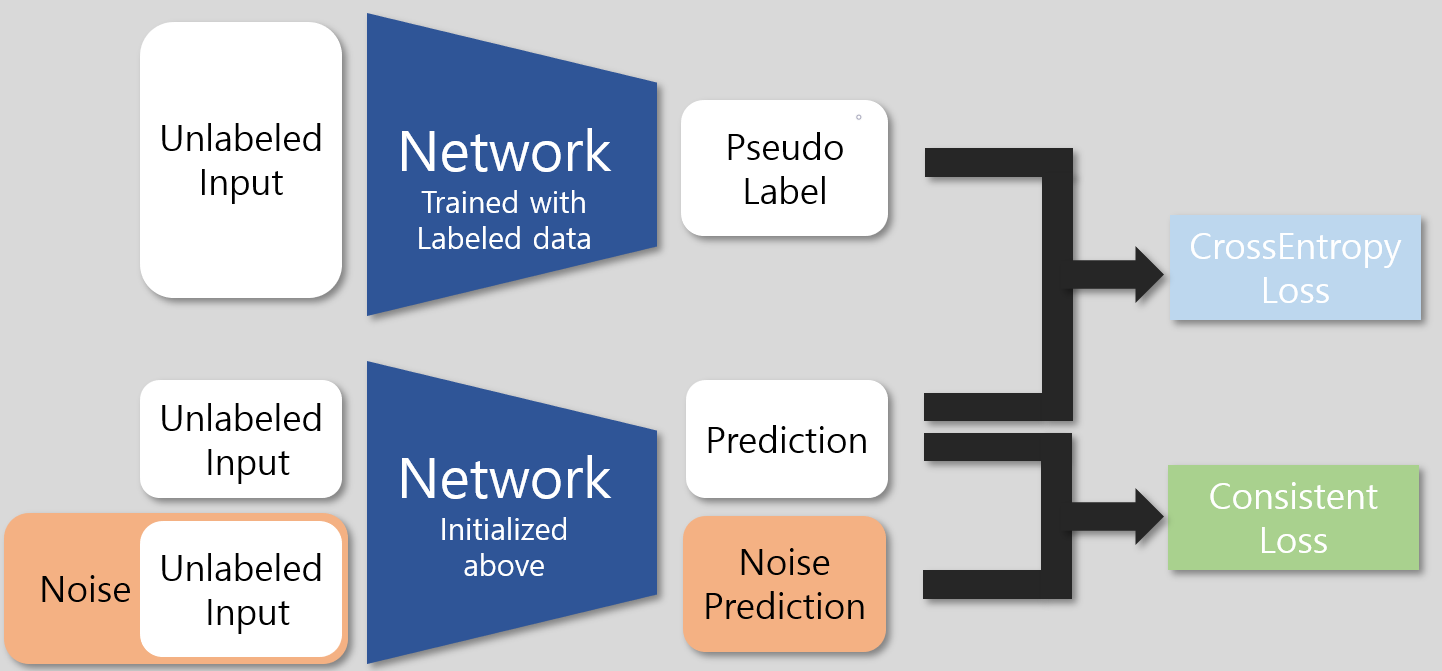
CrossEntropy Loss는 supervised learning에서 흔히 사용하는 분류 성능을 위한 task loss이다. Consistent Loss가 pseudo-label의 신뢰성을 높이기 위한 부분으로, 원본 데이터와 이것에 noise를 추가한 데이터의 prediction이 유사하게끔 만들어준다.
Noise가 끼든 안끼든 같은 데이터이므로 예측의 유사성을 높인다면 소량의 labeled 데이터로 학습된 network가 만든 pseudo-label의 신뢰성이 상승할 것이라는 가정을 깔고 있다.
Noisy Student Training
논문에서 제시한 Noisy Student Training은 위 두 방식들과 크게 두가지 차이점이 존재한다. 첫 번째는 KD와 달리 모델의 성능을 향상시키기 위함이므로, Teacher보다 같거나 큰 Studnet Network를 이용한다는 점이고, 두 번째는 Noise를 Teacher의 신뢰성 향상이 아닌 Studnet의 성능 향상을 위해 사용했다는 점이다.
이 외에도, 성능 향상을 위해 unlabeled data를 그대로 사용하지 않고, 샘플링(Pseudo-label당 샘플 수를 일정하게 만들어줌)을 거치거나, 작은 해상도로 모델을 학습시킨후 큰 해상도로 fine-tuning하는 등의 방법을 이용했다.
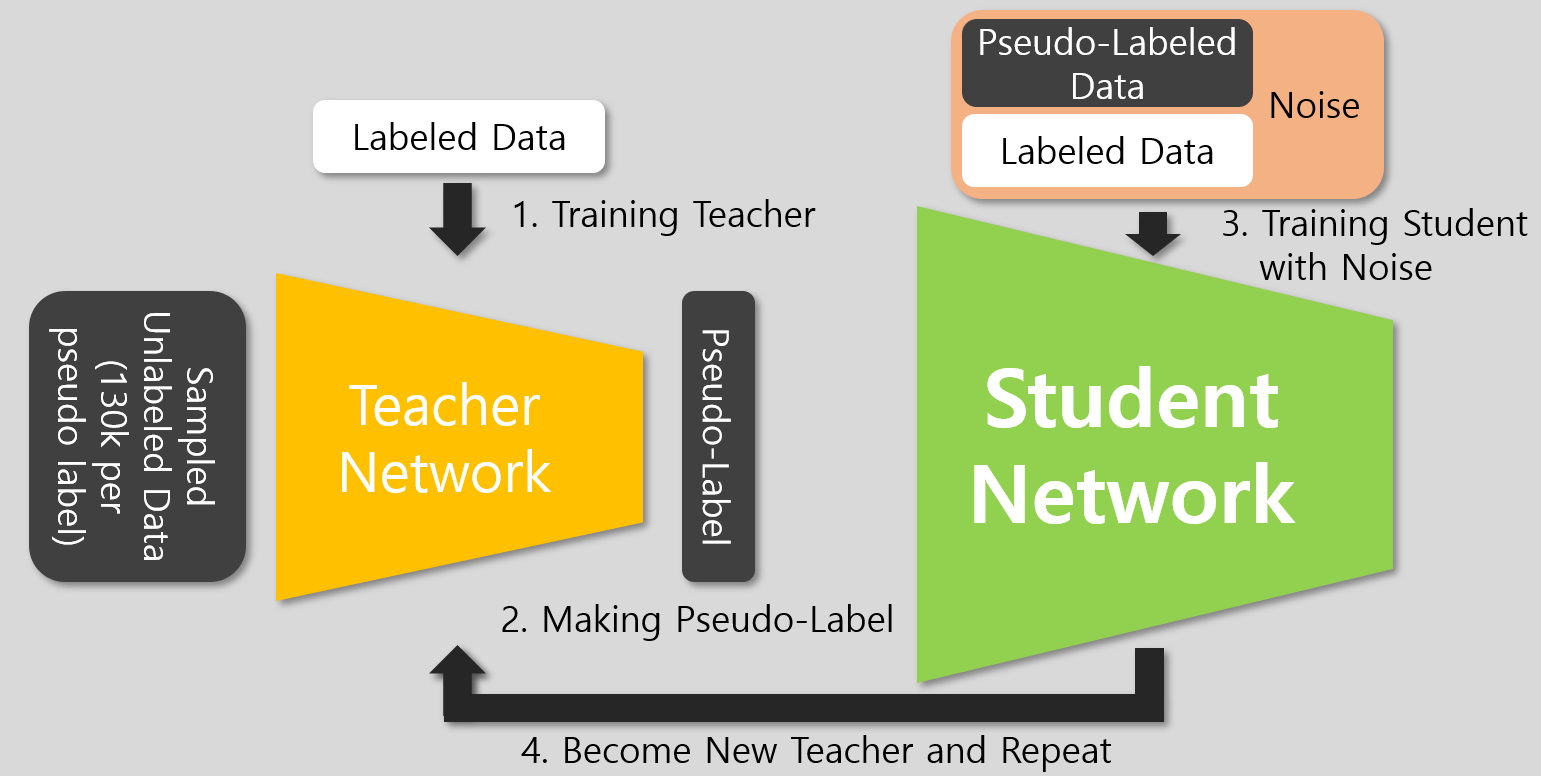
3단계에서 Teacher를 학습할때 이용한 labeled data와 pseudo-labeled이 할당된 unlabeled data를 모두 사용한다.
학습 과정은 위 그림과 같은데, 기존 방법들과의 차이점을 짚으면 앞서 말했듯 student가 더 커졌고, Noise를 사용하되 consistency regularization이 없다는 점이다. 4번도 추가된 것 처럼 보이지만 기존 방법에서도 사용되는 방법으로 학습된 Student Network를 새로운 Teacher로하여 동일 과정을 반복하는 것이다.
그런데, 첫 번째 차이점은 사실 KD와 Noisy Student의 학습 목적이 다르므로 이해가 되지만, Noise는 왜 필요할까? 기존 SSL에서 noise가 사용된 이유는 Teacher의 신뢰성 보장 때문이었다. 하지만, Noisy Studnet에서는 이미 좋은 성능을 보인 Efficient Net을 Teacher로 사용해 신뢰성이 보장되었으므로, consistency regularization이 필요 없고 따라서 noise도 필요없다. 그런데 저자들은 왜 사용했을까? 우선 noise가 성능에 끼친 영향부터 살펴보자.

Aug : Data Augmentaiton, SD : Stochastic Depth를 뜻한다.
위 실험은 EfficientNet-B5를 Teacher로 사용해서, Aug을 적용하지 않을때, SD, Dropout도 적용하지 않을때, Teacher에도 적용했을때의 성능을 보여준다. 저자들이 주장한대로 Noise가 효과가 있다. 사실 여기서도 의문점이 생긴다. SD나 Dropout, Aug는 단일 모델에 사용했을때 성능이 향상된 사례가 많고, 주로 overfitting을 방지하기 위해 사용되었다. 그럼 이 noise를 추가한게 이 논문의 novelty가 될 수는 없지 않을까?
실험 결과를 보면, 1.3M과 130M에서의 성능을 비교한다. 모델의 크기와 데이터셋의 크기가 overfitting과 관계가 깊은것은 잘 알려진 사실인데, 보통 데이터셋의 크기가 크면 overfitting되기 어렵다. 위 실험도 이를 비교하기 위한 실험으로, 1.3M이 overfitting된 것, 130M이 overfitting이 되지 않은 것으로 간단히 생각해보면 두가지 경우 모두에서 noise가 성능이 좋음을 볼 수 있다. 즉, noise는 overfitting 여부와 상관없이 모델의 성능을 향상시킨다.
결과적으로, 저자들이 주장한 것 처럼 Teacher보다 성능이 좋은 Student를 얻기 위해서는 Teacher가 아는 것 이상을 가르쳐야 하고, 이 역할을 noise가 수행한 것으로 볼 수 있다. 이는 제일 마지막 행도 뒷받침 해주는데, noise를 두 네트워크 모두에 적용했을때는 오히려 성능이 떨어짐을 확인할 수 있다. 그럼 여러 실험에서의 결과를 확인해보자.
실험들
ImageNet에서의 성능이 좋은것은 저자들의 주장대로라면 당연한 것이므로, 몇 가지 실험만 소개하겠다. 각 실험들은 다음을 의미한다.
-
위의 Noisy Student Training 그림에서 4번 과정이 없어도 잘 동작할까?

기존 SOTA인 EfficientNet보다 성능이 좋다.
-
기존 ImageNet기반 모델들이 어려워하는 것들도 잘 구분할까?

A는 ImageNet이 어려워하는 예재들, C는 corruption을 추가한 예제들, P는 rotation, scaling 등등을 적용했을때 모델이 어떻게 예측하는지를 확인하는 예제들이다. 검은색이 Noisy Student Training 모델의 응답이고, 빨간색이 EfficientNet의 응답이다. 훨씬 정확함을 볼 수 있다. 수치적으로도 표현 가능하지만 위 사진이 더 직관적이라 따로 표현하지 않았다.
-
적대적 공격에는 얼마나 버틸수 있을까?

Adversarial Example로 학습했을때 얼마나 견디는가에 관한 실험으로, Adversarial example은 사람의 육안으로는 변화가 없지만, 모델에게 잘못된 예측을 이끌어내도록 의도적으로 조작된 예제이다. Epsilon값이 클수록 더욱 공격성이 강한 예제라고 볼 수 있다. Noisy Student를 사용하면, 이를 위한 대비를 하지 않았음에도 EfficientNet보다 Robust하다.
결론
추가적인 Unlabeled data를 이용해서 모델의 성능은 물론 여러 면에서 장점을 보이는 Noisy Student Training을 제시한 논문이다. EffcientNet과 발표 날짜 차이가 얼마 안나는데도 훨씬 좋은 성능을 보여서 꽤 놀랍다. 특징은 다음과 같이 나타낼 수 있을듯
- Unlabeled 데이터셋으로 더 성능 좋은 모델을 얻는 방법
- 기존 방법들이 어려워하는 예제들에서도 좋은 성능을 보임
- 적대적 공격에도 강건함


Leave a comment